

アートパネル アートボード ドラクロワ 民衆を導く自由の女神 60x45 A2 壁掛け 絵 インテリア 名画 モダンアート 油絵 絵画 有名画 おすすめ 人気 高級 かわいい おしゃれ ポスター 玄関 リビング 部屋 店舗 風景画 自然 花 空 海 モノトーン 【LotNo.01】
こんにちは、monachan_papa です。
今回は Python による画像処理ということで、画像の類似判定について解説します。
まずは、画像の類似判定とは一体何?ということから。
例えば、「A」 という比較もと画像が1枚、「B、C、D」という比較さき画像が3枚あったとします。
このとき、B〜D はどれだけ A に似ているのか?つまり、類似度を算出するアルゴリズムを作りましょう!という話です。
さて、類似度と言えば、実はもうすごい身近なところで利用されています。
Google です。Googleの画像検索では類似画像検索といって、ある画像をもとにそれとよく似た画像を探し出す機能があります。
そして、こんな便利なことができるのは、画像をコンピュータが理解できるように数値化して演算しているからです。
今回、ご紹介する類似判定はもちろんGoogle のように高性能なものではありませんが、「画像を数値化して、解析し可視化する」 というノウハウについて学ぶことができる楽しい内容になっています。
また、データ分析では超定番の numpy、pandas、matplotlib をフル活用する内容ですので、機械学習の初学者の御方には特にオススメできるコンテンツとなります。
Jupter Notebook や Jupyter Lab を使いながら、逐一細かい挙動をインタラクティブに理解・確認しながら、ワークショップ風に進めていく構成にしてあります。
是非、本テーマを通して、python による機械学習の楽しさを体感していただけたらと思います。
今回の類似判定のテーマについて
以下のように設定しました。
どんな絵なのか知っている人も知らない人も以降から強引にスタートされます!
ドラクロワの名画である『民衆を導く自由の女神』と、Dragon AshのCD『Viva La Revolution』のアルバムジャケットはどれくらい似ているのか、可視化せよ。
ライブラリのインポート
今回、使用するライブラリは以下の5つとなります。まずはインポートしておきましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
from glob import glob
まずは画像を表示してみましょう
今回、比較もと画像を1枚、比較さき画像を3枚使います。類似判定が云々の前に、ウォーミングアップとしてこれら画像を、Jupter Notebook や Jupyter Lab に表示するところから始めてみましょう。
前提条件として、比較もと画像はカレントディレクトリ直下、3枚の比較さき画像はカレントディレクトリ配下の PNGフォルダに格納されているとします。
カレントディレクトリ
│
├── base_gazo.png
│
└─── PNG
├── 00_bentenya.png
├── 01_dragon_ash.png
└── 02_delacroix.png
比較もと画像パスは単独で変数に格納します。比較さき画像群パスはリスト変数に格納します。
# 比較もと画像、比較さき画像
moto_gazo, saki_gazos = 'base_gazo.png', sorted(glob('./PNG/*.png'))
moto_gazo, saki_gazos
('base_gazo.png',
['./PNG/00_bentenya.png',
'./PNG/01_dragon_ash.png',
'./PNG/02_delacroix.png'])
※画像ファイルを開いて、イメージオブジェクトを返す。
まずは、比較もと画像を開いて表示します。
この画像が、ドラクロワの名画である『民衆を導く自由の女神』になります。
# 比較もと画像
print(moto_gazo)
img = Image.open(moto_gazo)
img
base_gazo.png

base_gazo.png
続いて、比較さき画像群を表示します。比較さき画像群には、色々入っていますが、表示した後に説明します。
# 比較さき画像群
for saki_gazo in saki_gazos:
print(saki_gazo)
img = Image.open(saki_gazo)
display(img)
print('')
./PNG/00_bentenya.png

./PNG/00_bentenya.png
./PNG/01_dragon_ash.png

./PNG/01_dragon_ash.png
./PNG/02_delacroix.png
./PNG/02_delacroix.png
画像についての説明をします。
- 1枚目は、名古屋のちんどん べんてんや のCDアルバム『千客万来』のアルバムジャケットです。千客万来 [ べんてんや ]
- 2枚目は、Dragon Ash のCDアルバム『Viva La Revolution』のアルバムジャケットです。Viva La Revolution [ Dragon Ash ]
- 3枚目は、比較もと画像と全く同じ画像です。ファイル名が違うだけです。
さて、これら画像を人間の目で見るからに、どれが類似度が高そうで、低そうなのかはすぐに分かります。
では、大量に比較さき画像があった場合や、人間の目では判断が難しい場合はどうでしょうか?さすがにやってられませんよね。
そこで必要なのが、冒頭で述べた画像を数値データ化することなんです。
画像の数値データ化と前処理
画像の数値データ化自体は、numpy.arrayメソッドの引数にイメージオブジェクトを渡すことで簡単にできます。
しかし、類似判定をするための数値データ化には、いくつかの前処理が必要です。
※イメージオブジェクトを配列化したデータである ndarrayオブジェクト を返す。
前処理
今回、類似判定に使う画像はカラー画像であり例えば、もと画像をそのまま数値データ化した場合、以下のようになります。
img = Image.open(moto_gazo)
datas = np.array(img)
datas
array([[[ 3, 1, 15],
[ 5, 3, 17],
[ 4, 2, 16],
...,
[17, 29, 41],
[15, 28, 37],
[10, 24, 33]],
[[ 2, 0, 14],
[ 5, 3, 17],
[ 5, 3, 17],
...,
[23, 37, 50],
[21, 35, 46],
[17, 31, 42]],
[[ 2, 0, 14],
[ 4, 2, 16],
[ 6, 3, 20],
...,
[31, 44, 60],
[29, 42, 58],
[25, 38, 54]],
...,
[[21, 19, 22],
[19, 17, 20],
[18, 16, 19],
...,
[ 7, 7, 15],
[ 8, 8, 18],
[17, 17, 29]],
[[30, 28, 33],
[28, 26, 29],
[26, 24, 27],
...,
[ 9, 9, 17],
[11, 11, 21],
[20, 20, 32]],
[[30, 28, 33],
[30, 28, 31],
[29, 27, 30],
...,
[16, 16, 24],
[18, 18, 28],
[26, 26, 38]]], dtype=uint8)
データ量が多いので、省略化された状態で表示されています。
これがどのくらいのサイズ感かを調べてみましょう。以下のメソッドで調べることができます。
※配列の形状を返す
datas.shape
(253, 320, 3)
高さ 253ピクセル × 幅 320ピクセル で3次元配列(RGBである)になっていることが分かります。
まずはこういったデータをこれから前処理していくと思ってください。
具体的にどんな前処理をするのかですがズバリ、画像の正規化をします。内容は以下の通りです。
- 画像を「8 × 8 = 64ビット圧縮、グレースケール化」する。
- 画素値の平均値を取得する。
- ピクセルごとに、平均より小さい要素を 1 、それ以外は 0 に変換する。
以上のような正規化をすることにより、かなり数値データが扱いやすくなります。特にグレースケール化は画像処理において、基本となる前処理です。3次元配列だったものが、2次元配列になります。
なお、現段階で何か難しいなあ、と感じても全く問題ありません。以降で正規化したものを可視化するので、そのときにかなりイメージが固まるはずです。
画像の正規化
比較もと画像、比較さき画像ともにすべて正規化をします。
# 正規化時の一辺のサイズ
size = 8
# 画像の正規化
def normalize(file):
img = Image.open(file)
img = img.convert('L').resize((size, size), Image.LANCZOS) # 圧縮とグレースケール化
px = np.array(img) # 画像を配列化
avg = px.mean() # 画素値の平均値
px = 1 * (px < avg) # 平均より小さい要素を1にする
return px・グレースケールに変換したイメージオブジェクトを返す。
・img はイメージオブジェクト
・ 指定サイズ (x, y) にリサイズしたイメージオブジェクトを返す
・ 引数 Image.LANCZOS は高品質にリサイズするための指定
・ img はイメージオブジェクト
・配列要素の平均を返す
# 正規化後の画像表示
def show(px):
fig = plt.figure(figsize=(2.5, 2.5), facecolor='cyan')
ax = fig.add_subplot(111)
ax.set_xticks([0, 1, 2, 3, 4, 5, 6, 7, 8])
ax.set_yticks([0, 1, 2, 3, 4, 5, 6, 7, 8])
ax.imshow(px, cmap='binary')
plt.show()
# 正規化と正規化後の画像表示
def normalize_and_show(file_name, px):
print('前処理後', file_name)
print('')
px = normalize(file_name)
print(px)
print('')
show(px)
print('')
前処理後の「比較もと画像」
前処理を「比較もと画像」にすると、配列と画像イメージはこんな感じになります。
matplotlib の使い方については、過去に詳しく解説しています。
Python グラフ描画 Matplotlibの使い方【初心者向け完全保存版】
moto_gazo_px = normalize(moto_gazo)
normalize_and_show(moto_gazo, moto_gazo_px)
前処理後 base_gazo.png
[[1 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0]
[1 1 1 0 0 0 0 0]
[1 1 1 1 0 1 0 0]
[1 1 1 1 1 1 0 0]
[1 1 1 1 1 1 1 1]
[1 0 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]]
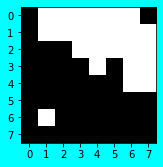
かなりイメージが湧いたと思います。
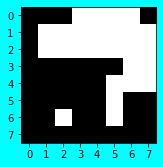
前処理後の「比較さき画像群」
同様にして、前処理を「比較さき画像群」に対しても実施します。
saki_gazos_px = [normalize(saki_gazo) for saki_gazo in saki_gazos]
# 比較さき画像1枚目
normalize_and_show(saki_gazos[0], saki_gazos_px[0])
# 比較さき画像2枚目
normalize_and_show(saki_gazos[1], saki_gazos_px[1])
# 比較さき画像3枚目
normalize_and_show(saki_gazos[2], saki_gazos_px[2])
前処理後 ./PNG/00_bentenya.png
[[1 1 0 1 1 1 1 1]
[1 0 0 1 0 1 1 1]
[1 1 1 1 0 0 0 0]
[1 1 1 1 1 1 0 0]
[1 0 1 0 1 1 0 0]
[1 0 0 1 0 0 1 0]
[0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0]]
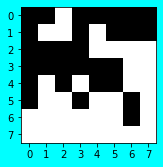
前処理後 ./PNG/01_dragon_ash.png
[[1 1 1 0 0 0 0 1]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 1 1 1 1 1 0 0]
[1 1 1 1 1 0 0 0]
[1 1 1 1 1 0 1 1]
[1 1 0 1 1 0 1 1]
[1 1 1 1 1 1 1 1]]
前処理後 ./PNG/02_delacroix.png
[[1 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0]
[1 1 1 0 0 0 0 0]
[1 1 1 1 0 1 0 0]
[1 1 1 1 1 1 0 0]
[1 1 1 1 1 1 1 1]
[1 0 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]]

今すぐ試したい!機械学習・深層学習(ディープラーニング)画像認識プログラミングレシピ [ 川島 賢 ]
類似判定
前処理が終わったので、あとはどのように類似判定をするかということだけです。
具体的にどんな手法で判定するかですが、以下が算出できれば判定処理ができます。
各ピクセル値とは、前処理で正規化された配列のことです。
「比較もと画像の配列」と「比較さき画像群の配列」を、比較演算子== を使ってチェックすることで、各ピクセルごとに一致しているのか簡単にチェックすることができます。そして、チェック結果は配列の各要素ごとに True または False で返されるので、簡単に合計をとることができます。
以下のコードは、上記の説明をまとめたものです。
何と、実質たった1行で書けます。
# 比較もと画像と一致したピクセルの個数合計
match_cnt = [(moto_gazo_px == saki_gazo_px).sum() for saki_gazo_px in saki_gazos_px]
match_cnt
[32, 54, 64]
結果を見ると、良い感じです。
冒頭の説明と重複しますが、比較さき画像群は以下のようなものでした。
- 1枚目は、名古屋のちんどん べんてんや のCDアルバム『千客万来』のアルバムジャケットです。千客万来 [ べんてんや ]
- 2枚目は、Dragon Ash のCDアルバム『Viva La Revolution』のアルバムジャケットです。Viva La Revolution [ Dragon Ash ]
- 3枚目は、比較もと画像と全く同じ画像です。ファイル名が違うだけです。
さあ、ここまで来れば残る工程はただひとつ。
各ピクセル値ごとの一致数がどれだけあれば、類似判定で OKなのか、NGなのか閾値を決めたり、類似判定結果を可視化する楽しい工程だけです。
判定結果の可視化
判定結果は、pandas.DataFrame に表示することで、簡単にですが可視化することができます。
データフレームの列項目に以下を設けます。
- 比較さき画像名
- 一致px数
- 不一致px数
- 類似度
- 判定
以下のコードは、判定列以外 のデータフレームをまず作成しています。
datas = {
'比較さき画像名': saki_gazos,
'一致px数': match_cnt,
'不一致px数': [(size*size)-m for m in match_cnt],
'類似度': [(m/(size*size))*100 for m in match_cnt]
}
df = pd.DataFrame(datas)
df
| 比較さき画像名 | 一致px数 | 不一致px数 | 類似度 | |
|---|---|---|---|---|
| 0 | ./PNG/00_bentenya.png | 32 | 32 | 50.000 |
| 1 | ./PNG/01_dragon_ash.png | 54 | 10 | 84.375 |
| 2 | ./PNG/02_delacroix.png | 64 | 0 | 100.000 |
続いて、作成されたデータフレームをもとに、判定列を追加します。
今回は類似度が 80パーセント以上であれば OK とします。
similar = 80 # 合格ライン
df['判定'] = ['OK' if x >= similar else 'NG' for x in df['類似度']]
df
| 比較さき画像名 | 一致px数 | 不一致px数 | 類似度 | 判定 | |
|---|---|---|---|---|---|
| 0 | ./PNG/00_bentenya.png | 32 | 32 | 50.000 | NG |
| 1 | ./PNG/01_dragon_ash.png | 54 | 10 | 84.375 | OK |
| 2 | ./PNG/02_delacroix.png | 64 | 0 | 100.000 | OK |
リスト内包表記、三項演算子を組み合わせたコードになっています。三項演算子を使うことで、代入の条件分岐を1行で書くことが可能です。
※条件が True なら戻り値1、条件が False なら戻り値0 を返す
リスト内包表記については、過去に詳しく解説しています。
Pythonの内包表記を初心者向けに解説。リスト・集合・辞書内包表記【Python tips】
最後に比較もと画像の表示、そして「正規化前の比較さき画像」と判定結果をループ表示して完成させます。
# 比較もと画像
img = Image.open(moto_gazo)
display(img)
print('比較もと画像名:', moto_gazo)
print('-'*50)
print('')
# 比較さき画像群
for saki_gazo in saki_gazos:
img = Image.open(saki_gazo)
display(img)
display(df[df.比較さき画像名==saki_gazo])
print('')
base_gazo.png
比較もと画像名: base_gazo.png
--------------------------------------------------
./PNG/00_bentenya.png
| 比較さき画像名 | 一致px数 | 不一致px数 | 類似度 | 判定 | |
|---|---|---|---|---|---|
| 0 | ./PNG/00_bentenya.png | 32 | 32 | 50.0 | NG |
/PNG/01_dragon_ash.png
| 比較さき画像名 | 一致px数 | 不一致px数 | 類似度 | 判定 | |
|---|---|---|---|---|---|
| 1 | ./PNG/01_dragon_ash.png | 54 | 10 | 84.375 | OK |
/PNG/02_delacroix.png
| 比較さき画像名 | 一致px数 | 不一致px数 | 類似度 | 判定 | |
|---|---|---|---|---|---|
| 2 | ./PNG/02_delacroix.png | 64 | 0 | 100.0 | OK |
以上で、完成しました。
ドラクロワの名画である『民衆を導く自由の女神』と、Dragon AshのCDアルバム『Viva La Revolution』のアルバムジャケットはどれくらい似ているのか、可視化できました。
結論、似てる度 80超えだった!
類似判定可視化コードの整理
以下のコードはこれまでの解説において、類似判定可視化で必要な部分だけをまとめたコードになります。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
from glob import glob
# 比較もと画像、比較さき画像
moto_gazo, saki_gazos = 'base_gazo.png', sorted(glob('./PNG/*.png'))
# 正規化時の一辺のサイズ
size = 8
# 画像の正規化
def normalize(file):
img = Image.open(file)
img = img.convert('L').resize((size, size), Image.LANCZOS) # 圧縮とグレースケール化
px = np.array(img) # 画像を配列化
avg = px.mean() # 画素値の平均値
px = 1 * (px < avg) # 平均より小さい要素を1にする
return px
# 比較もと画像、比較さき画像の正規化後の配列(ピクセル値
moto_gazo_px = normalize(moto_gazo)
saki_gazos_px = [normalize(saki_gazo) for saki_gazo in saki_gazos]
# 比較もと画像と一致したピクセルの個数合計
match_cnt = [(moto_gazo_px == saki_gazo_px).sum() for saki_gazo_px in saki_gazos_px]
# /////類似判定と可視化/////
datas = {
'比較さき画像名': saki_gazos,
'一致px数': match_cnt,
'不一致px数': [(size*size)-m for m in match_cnt],
'類似度': [(m/(size*size))*100 for m in match_cnt]
}
df = pd.DataFrame(datas)
similar = 80 # 合格ライン
df['判定'] = ['OK' if x >= similar else 'NG' for x in df['類似度']]
# 比較もと画像
img = Image.open(moto_gazo)
display(img)
print('比較もと画像名:', moto_gazo)
print('-'*50)
print('')
# 比較さき画像群
for saki_gazo in saki_gazos:
img = Image.open(saki_gazo)
display(img)
display(df[df.比較さき画像名==saki_gazo])
print('')
今回は画像の正規化において、シンプルで説明も分かりやすい 8 × 8 = 64ビット圧縮を使いました。
しかし、画像によっては判定の精度も悪くなることもあります。精度が悪い場合は、以下のサイズ等への検討や閾値(類似度を何パーセントでOKにするか)を厳しめにすると良いでしょう。
- 16 × 16 = 256ビット圧縮
- 32 × 32 = 1024ビット圧縮
プログラムは、変数size、変数similar の各数値を変えるだけで良い仕様になっています。
以上で、Python類似画像判定でドラクロワ名画とDragon Ashのアルバムジャケの検証をするについての解説を終わります。
今回は類似画像判定をテーマにしましたが、Pythonによる画像処理で出来ることは、この他にもたくさんあります。ディープ・ラーニングも取り入れれば、もっとすごいことも可能となります。スマホの顔認証など身近な例ですね。
画像処理にもっと詳しく触れてみたい!という御方は、今すぐ試したい!機械学習・深層学習(ディープラーニング)画像認識プログラミングレシピ [ 川島 賢 ]が大変おすすめです。もし、画像処理でやってみたい事がすぐにでも思いつかない場合でも、お題がちゃんと用意されています。
例えば、犬なのか猫なのかを認識する犬猫認識など。Pythonで画像処理をもっと楽しみましょう。
今すぐ試したい!機械学習・深層学習(ディープラーニング)画像認識プログラミングレシピ [ 川島 賢 ]
また、爆速で Python画像処理や機械学習を学びたい御方にはプログラミングスクールを考えるのも、ひとつの手です。独学よりも効果が出やすいですが、いかんせん投資がけっこうかかります。しかし、techgym というスクールは通うか通わないかは別として、無料のサンプルテキスト&解説動画がもらえます。これをとりあえず getしてまずは試しに体験学習するのもありでしょう。


コメント