
15Stepで踏破自然言語処理アプリケーション開発入門 PythonとKerasで基礎から一巡/土屋祐一郎【3000円以上送料無料】
こんにちは、monachan_papaです。
前回まで形態素解析について数回やってきましたので、今回は新しいことを取り挙げてみたいと思います。まずは、言葉の説明よりもこちらの画像をご覧ください。
ドーン!
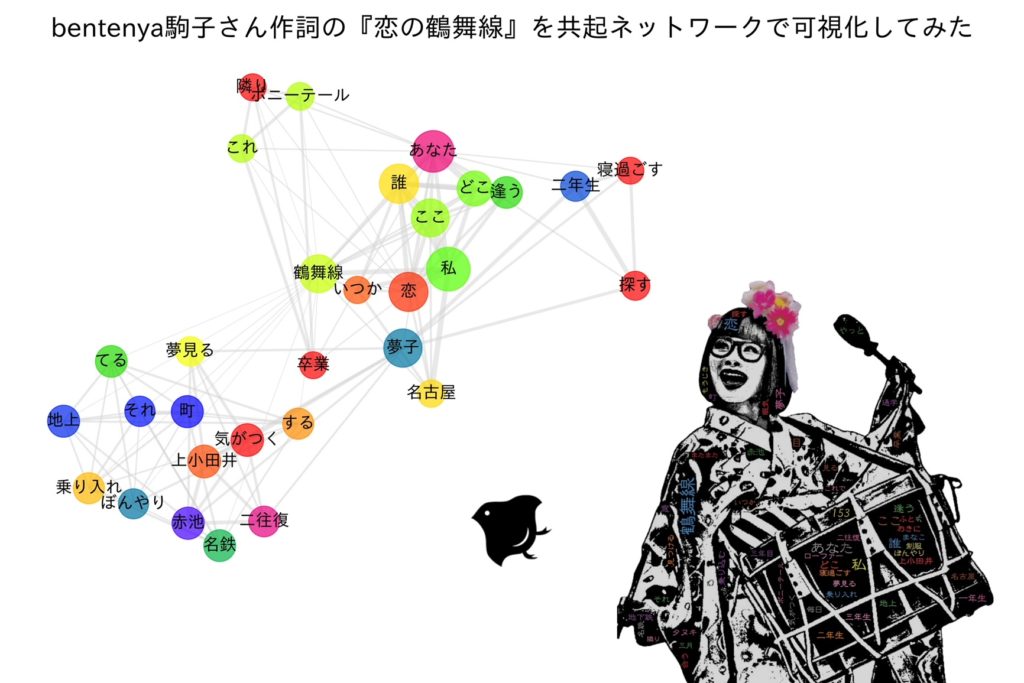
共起ネットワークのイメージ
 共起ネットワークです!
共起ネットワークです!
共起とは?
共起ネットワークのことをざっくり説明すると、文章の中で或る単語Aと或る単語Bが同時に出現している様子をネットーワーク図にして可視化したものです。
そして、共起という言葉についてですが、これは普段誰もが、実はとても馴染みがあるものなんです。例えば、メチャクチャうまいラーメン屋の新規開拓に行き詰まったとき、インターネットに頼ることがあるかもしれません。そのとき、、、、
-
ラーメン 行列
-
ラーメン 人気
-
ラーメン 名古屋
-
ラーメン 二郎系
などのワードで検索をかけることが想定されます。上記で言えば、それぞれの言葉は関連性が強いものを組み合わせながら、自然とやっています。
こんな感じで、とても分かりやすいものだと思います!
多分、あなたもきっとほぼ毎日、共起な毎日を送っておられると思います。
共起ネットワークを作ろうぜ!
今回も例によって、私の推しである名古屋のちんどん べんてんやの駒子さんが作詞作曲された名曲、恋の鶴舞線の歌詞を題材にやっていきたいと思います。
内容はこれまでやってきたことよりレベルアップしますが、「共起ネットワーク図を作る」という或る意味で作品制作なので、楽しんでやれるはずです!
ソースについては、主にJupyter NoteBook または Jupyter Lab上で逐一、入出力をしっかりと、着実に、確認しながら理解できる細かい単位で書いていきますので、楽しく共起ネットワーク図を作りましょう。
前半については、これまでの投稿で取り挙げてきた内容がたくさん登場しますので、まずは気楽にいきましょう!
各種ライブラリのインポート
使用するライブラリをまずは一気にインポートします。
今回の注目ライブラリは、Networkx です。共起ネットワークを作るにあたり要となるものです。 グラフ分析、ネットワーク理論構築に使用されるライブラリです。その他、特にコメントが要ると思われるものについてのみコメントをしておきました。
import MeCab
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib # 可視化時の日本語出力のために必要
import itertools # 共起語の組合せ作成に使用
import networkx as nx # 共起ネットワーク作成に使用
from collections import Counter
from datetime import datetime
テキストファイル読み込み、形態素解析
地下鉄通学 一年生 眠気まなこで 乗り込んだ
夢見る夢子は 気がつけば 上小田井赤池 二往復
ここは誰? 私はどこ? あなたに逢いたい 恋の鶴舞線
名古屋のちんどん べんてんや 駒子さん作詞「恋の鶴舞線」の歌詞を手打ちしたテキストファイルをあらかじめkoitsuru.txt で用意しました。
※本ブログにて引用しているのは、歌詞の冒頭部分のみです。実際に用意したテキストファイルは全歌詞が入力されています。
テキストファイルを読み込んで、形態素解析します。前回の記事で、この辺りのことを取り挙げています。
今回のポイントですが、
なぜ、行単位レベルなのかと言うと、このあと行単位レベルで共起する単語を取得する必要があるからです。
# テキスト読み込み
with open('koitsuru.txt', 'r') as f:
words = f.read()
# 行単位で分割
words = words.splitlines()
# 引数にユーザ辞書を指定
t = MeCab.Tagger(r'-u userdic.dic')
# 形態素解析、結果を行単位で格納する
lines = []
for word in words:
datas = []
node = t.parseToNode(word)
while node:
# 表層形
surface = node.surface
# 品詞が活用情報など
feature = node.feature.split(',')
# 品詞、原形
pos, origin = feature[0], feature[6]
# 指定品詞のみ
if pos in ['名詞', '動詞', '形容詞', '副詞', 'カスタム名詞']:
# 原形があるなら原形、ない場合は表層形
word = origin if origin != '*' else surface
datas.append(word)
node = node.next
lines.append(datas)
lines
[['地下鉄', '通学', '一年生', '眠気', 'まなこ', '乗り込む'],
['夢見る', '夢子', '気がつく', '上小田井', '赤池', '二往復'],
['ここ', '誰', '私', 'どこ', 'あなた', '逢う', '恋', '鶴舞線'],
['あなた', '探す', '二年生', '夢子', '寝過ごす'],
['窓', '外', '153', 'ふと', '見る', 'タヌキ', '目', '合う'],
['ぼんやり', 'する', 'てる', '地上', '町', '名鉄', '乗り入れ', 'それ', '鶴舞線'],
['もう', 'じき', '三月', '三年生', 'おきに', 'ローファー', '三年目'],
['毎日', '制服', '目', '追う', 'やっと', '見つける'],
['あなた', '隣り', 'ポニーテール', 'これ', '卒業', '恋', '鶴舞線'],
['ここ', '誰', '私', 'どこ', 'あなた', '逢う', '恋', '鶴舞線'],
['ここ', '名古屋', '私', '私', 'いつか', '誰', '恋', '鶴舞線', '恋', '鶴舞線']]
結果を全件確認します。Mecabユーザー辞書に設定した内容も反映されているので、OKとします。
共起語の生成
行単位に形態素解析ができたので、行単位で共起する2語の組合せを作っていきます。作成はitertoolモジュールのcombinations関数を使えば一発です。 これについては、過去の記事でも取り上げています。
# 各行における2語の組み合わせ
cmb_lines = [list(itertools.combinations(line, 2)) for line in lines]
cmb_lines[:2]
[[('地下鉄', '通学'),
('地下鉄', '一年生'),
('地下鉄', '眠気'),
('地下鉄', 'まなこ'),
('地下鉄', '乗り込む'),
('通学', '一年生'),
('通学', '眠気'),
('通学', 'まなこ'),
('通学', '乗り込む'),
('一年生', '眠気'),
('一年生', 'まなこ'),
('一年生', '乗り込む'),
('眠気', 'まなこ'),
('眠気', '乗り込む'),
('まなこ', '乗り込む')],
[('夢見る', '夢子'),
('夢見る', '気がつく'),
('夢見る', '上小田井'),
('夢見る', '赤池'),
('夢見る', '二往復'),
('夢子', '気がつく'),
('夢子', '上小田井'),
('夢子', '赤池'),
('夢子', '二往復'),
('気がつく', '上小田井'),
('気がつく', '赤池'),
('気がつく', '二往復'),
('上小田井', '赤池'),
('上小田井', '二往復'),
('赤池', '二往復')]]
結果を数件確認します。リストのリスト形式で、各行の2語の組合せができました。
共起ネットワーク作成の準備
共起語の生成ができました。これより共起ネットワークを作っていきたいと思いますが、まだ色々と準備が必要です。
準備についてですが、基本はPandasのDataFrameをフル活用して進めていきたいと思います。
Jaccard係数による共起語の重み算出
共起ネットワークでは、共起する単語同士はエッジ(辺)で繋がれています。このとき、この繋がり度合いをエッジの太さによって表現することができます。これを重みを与えると呼びます。今回、この繋がり度合いを算出するために、Jaccard係数を用います。
Jaccard係数を今回のケースで説明すると、共起する単語同士(以降、便宜的に単語AB)がどれくらい繋がりがあるかを表す指標です。この指標は単語Aと単語Bの和集合の数における、単語Aと単語Bの積集合の数の割合で算出できます。式で書くと、以下のようになります。
Jaccard係数 = (単語A、単語Bの積集合の数) ÷ (単語A、単語Bの和集合の数)
実際に一例を示します。
- 単語Aが含まれる行が7つ
- 単語Bが含まれる行が5つ
- 単語A、単語Bの両方がある行が2つ
このときJaccard係数は、2 ÷ (7 + 5 – 2) = 0.5 となります。
以上を踏まえ、Jaccard係数を求めていきます。以下の手順でJaccard係数を導き出します。
- 単語A、単語Bの積集合の数
- 単語A、単語Bの和集合の数
- Jaccard係数算出
単語A、単語Bの積集合の数
現時点で、各行における2語の組合せは変数cmb_linesにリストのリスト形式で格納されいているので、これを一つのリストに結合させます。
# 組合せ結合
words = []
for cmb_line in cmb_lines:
words.extend(cmb_line)
words[:3]
[('地下鉄', '通学'), ('地下鉄', '一年生'), ('地下鉄', '眠気')]
結果を数件確認します。問題なく一つのリストに結合できています。さて、ここから一発で積集合の数が出せます。collectionモジュールのCounterクラスを使います。この結果をPandasのDataFrameで管理しながら最後まで進めていきます。
# 単語Aと単語Bの積集合カウント
word_count = Counter(words)
word_A = [k[0] for k in word_count.keys()]
word_B = [k[1] for k in word_count.keys()]
intersection_cnt = list(word_count.values())
df = pd.DataFrame({'WORD_A': word_A, 'WORD_B': word_B, 'ITS_CNT': intersection_cnt})
df.head()
| WORD_A | WORD_B | ITS_CNT | |
|---|---|---|---|
| 0 | 地下鉄 | 通学 | 1 |
| 1 | 地下鉄 | 一年生 | 1 |
| 2 | 地下鉄 | 眠気 | 1 |
| 3 | 地下鉄 | まなこ | 1 |
| 4 | 地下鉄 | 乗り込む | 1 |
結果を数件確認します。DataFrameに格納されました。
単語A、単語Bの和集合の数
さて、単語A、単語Bの和集合の数を出したいのですが、少々面倒くさいです。しかし、単語A、単語Bのカウントが出来さえすれば、
以上で、簡単に単語A、単語Bの和集合の数が算出できます。そのための準備が以下となります。
# 単語A、単語Bのカウント
word_A_cnt = df['WORD_A'].value_counts()
df1 = word_A_cnt.reset_index()
df1.rename(columns={'index': 'WORD_A', 'WORD_A': 'WORD_A_CNT'}, inplace=True)
word_B_cnt = df['WORD_B'].value_counts()
df2 = word_B_cnt.reset_index()
df2.rename(columns={'index': 'WORD_B', 'WORD_B': 'WORD_B_CNT'}, inplace=True)
# 左外部結合
df = pd.merge(df, df1, how='left', on='WORD_A')
df = pd.merge(df, df2, how='left', on='WORD_B')
df.head()
| WORD_A | WORD_B | ITS_CNT | WORD_A_CNT | WORD_B_CNT | |
|---|---|---|---|---|---|
| 0 | 地下鉄 | 通学 | 1 | 5 | 1 |
| 1 | 地下鉄 | 一年生 | 1 | 5 | 2 |
| 2 | 地下鉄 | 眠気 | 1 | 5 | 3 |
| 3 | 地下鉄 | まなこ | 1 | 5 | 4 |
| 4 | 地下鉄 | 乗り込む | 1 | 5 | 5 |
単語A、単語Bカウント結果をそれぞれ別のDataFrameに格納します。そして、既存のDataFrameとこれらを左外部結合します。ここまで来たらあとは最後まで楽勝です!
# 単語A、単語Bの和集合カウント
df['UNION_CNT'] = (df['WORD_A_CNT'] + df['WORD_B_CNT']) - df['ITS_CNT']
df.head()
| WORD_A | WORD_B | ITS_CNT | WORD_A_CNT | WORD_B_CNT | UNION_CNT | |
|---|---|---|---|---|---|---|
| 0 | 地下鉄 | 通学 | 1 | 5 | 1 | 5 |
| 1 | 地下鉄 | 一年生 | 1 | 5 | 2 | 6 |
| 2 | 地下鉄 | 眠気 | 1 | 5 | 3 | 7 |
| 3 | 地下鉄 | まなこ | 1 | 5 | 4 | 8 |
| 4 | 地下鉄 | 乗り込む | 1 | 5 | 5 | 9 |
結果を数件確認します。計算結果に問題ないことが確認できました。
Jaccard係数算出
先程の予告通り、楽勝です。積集合の数を和集合の数で割るだけで終わりです。
# Jaccard係数
df['JACCARD'] = df['ITS_CNT'] / df['UNION_CNT']
df.head()
| WORD_A | WORD_B | ITS_CNT | WORD_A_CNT | WORD_B_CNT | UNION_CNT | JACCARD | |
|---|---|---|---|---|---|---|---|
| 0 | 地下鉄 | 通学 | 1 | 5 | 1 | 5 | 0.200000 |
| 1 | 地下鉄 | 一年生 | 1 | 5 | 2 | 6 | 0.166667 |
| 2 | 地下鉄 | 眠気 | 1 | 5 | 3 | 7 | 0.142857 |
| 3 | 地下鉄 | まなこ | 1 | 5 | 4 | 8 | 0.125000 |
| 4 | 地下鉄 | 乗り込む | 1 | 5 | 5 | 9 | 0.111111 |
結果を数件確認します。
以上で、共起ネットワークを作成するための準備が整いました。この後、このDataFrameのデータを元に、共起ネットワークを作成していきます。
15Stepで踏破自然言語処理アプリケーション開発入門 PythonとKerasで基礎から一巡/土屋祐一郎【3000円以上送料無料】
共起ネットワーク作成
用語説明
共起ネットワーク作成にあたり、少し用語について説明ます。
本ブログの初めに載せた共起ネットワークは色々と特徴がありますよね。
- ネットワーク = グラフ = Graph
- 頂点 = ノード = node
- 辺 = エッジ = edge
とりあえず、これだけ分かればまずは良いと思います。頂点というのは単語が入っているマル印のところです。残りについては、説明は不要かと思います。
作成手順と実際の作成まで
ざっと、以下の手順で実施します。
- Graphオブジェクト作成
- node追加
- edge追加
- node描画
- edge描画
- ラベル描画
- ネットワーク可視化
メソッドの詳細などはマニュアルを読めば分かると思いますが、似たようなメソッドがあり過ぎで頭痛くなりそうです。例えるなら、Matplotlibを初めて勉強したときの感覚に似ていました。以上より、なるべく統一的なメソッド形式で書きました。可視化の手順についても同様です。
以下、共起ネットワークを可視化し、結果を保存するところまで一気に書いてあります。
fig = plt.figure(facecolor='ivory', figsize=(15,15), dpi=600)
ax = fig.add_subplot(111)
# グラフオブジェクト作成
G = nx.Graph()
# /////node、edge追加/////
# node
# 単語A、単語Bの重複排除して直列化
nodes = list(set(df['WORD_A'].tolist() + df['WORD_B'].tolist()))
for node in nodes:
G.add_node(node)
# G.add_nodes_from(nodes) # for文を使わない場合はこのメソッド
# edge
for i in range(len(df)):
row = df.iloc[i]
G.add_edge(row['WORD_A'], row['WORD_B'], weight=row['JACCARD'])
# /////node、edge、ラベル描画等/////
# グラフレイアウト
pos = nx.spring_layout(G, k=0.3) # k = node間反発係数
# 重要度決定アルゴリズム(重要なnodeを見つけ分析する)
pr = nx.pagerank(G)
# node
nx.draw_networkx_nodes(
G, pos, node_color=list(pr.values()),
cmap='prism',
alpha=0.7,
node_size=[70000 * v for v in pr.values()]
)
# edge
nx.draw_networkx_edges(
G,
pos,
alpha=0.5,
edge_color="lightgrey",
width=[d["weight"] * 20 for (u, v, d) in G.edges(data=True)])
# 日本語ラベル
nx.draw_networkx_labels(G, pos, font_size=18, font_family='IPAexGothic', font_weight="bold")
# /////結果出力等/////
plt.axis('off')
plt.tight_layout()
plt.title('bentenya駒子さん作詞の『恋の鶴舞線』を共起ネットワークで可視化してみた', fontsize=28)
today = datetime.now().strftime('%Y%m%d')
file_name = f'共起ネット_result_{today}.png'
plt.savefig(file_name, dpi=600)
plt.show()
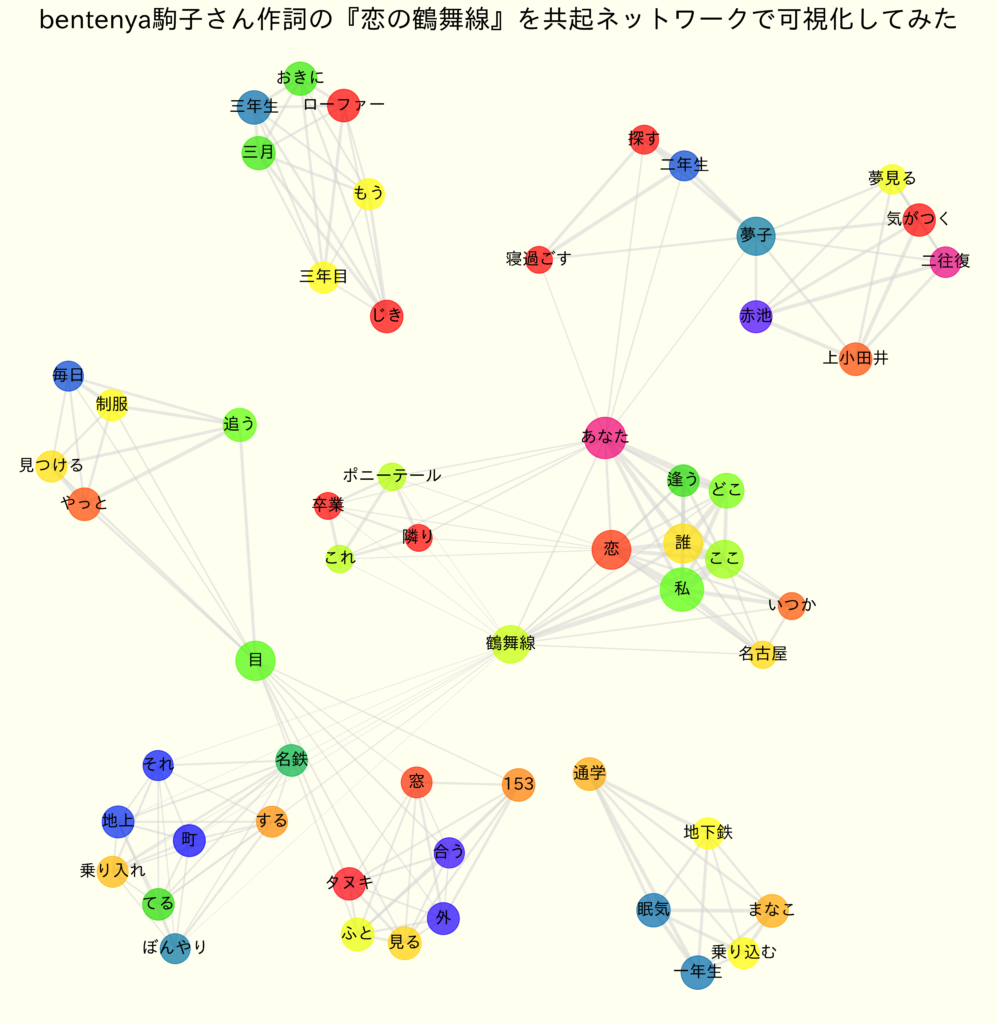
こんな感じで共起ネットワークができました。
「自分の好きな題材でやって、成果品を出す」
というのは、やはり一番楽しいことです。
今回は共起ネットワーク図でしたが、楽しみがもっと欲しい御方には、15Stepで踏破自然言語処理アプリケーション開発入門 PythonとKerasで基礎から一巡/土屋祐一郎【3000円以上送料無料】が大変おすすめです。対話エージェントといういわゆる作品を作りながら自然言語処理が学べて、一石二鳥です。
15Stepで踏破自然言語処理アプリケーション開発入門 PythonとKerasで基礎から一巡/土屋祐一郎【3000円以上送料無料】
また、爆速で自然言語処理を学びたい御方にはプログラミングスクールを考えるのも、ひとつの手です。独学よりも効果が出やすいですが、いかんせん投資がけっこうかかります。しかし、techgymというスクールは通うか通わないかは別として、無料のサンプルテキスト&解説動画がもらえます。これをとりあえず getしてまずは試しに体験学習するのもありでしょう。


コメント