
こんにちは、monachan_papaです。
前回は自然言語処理とは?についてやりました。
今回は自然言語処理の第一歩にいよいよ踏み込んでいきます!
自然言語処理の実用例
私たち人間が普段話している言葉や文章の膨大な塊を、コンピュータに何か処理してもらいたいとするとき、どんなことがあるでしょうか?
実用例としては以下のようなものがあります。
- 文字予測変換
- 音声アシスタント
- 検索エンジン
- 文章要約
- 感情分析
- 文章自動生成
上3つは誰もが使ったことがあるといっても良いです。 iPhoneを使っている御方なら音声アシスタントであるSiriを一度くらいは使ったことがあるでしょう。なかには、ヘビーユーザーの御方もいらっしゃるかもしれませんね。
でも、これらには事前に準備が必要です。人間 対 コンピュータなので、コンピュータが分かるように、そして可能な限り処理がしやすいようにしておいてあげることが必要です。
これを前処理といいます。
形態素解析とは?
前処理のファーストステップとして、文章を単語に分割します。文章の塊をコンピュータにあげるより、単語単位でコンピュータにあげた方が、より正確にコンピュータは理解することができるからです。
そして、単語単位に分割すれば、各単語に番号を振って数値の配列としてかなりコンピュータが扱いやすくなります。
男は黙ってサッポロビール
これを分割してみます。
| 単語 | 番号 |
|---|---|
| 男 | 0 |
| は | 1 |
| 黙っ | 2 |
| て | 3 |
| サッポロビール | 4 |
こんな感じで単語に分割することをわかち書きといいます。
しかし、前回少し書きましたがこの単語単位。英語はスペース区切りになっているから良いのですが、日本語はそうではないので、いわゆる料理するには一手間かかります!
でも、大丈夫です!ありがたいことに料理するための大変便利なマシンがあるんです。
後で詳しく解説しますがこのマシンは、文章を形態素(文章を構築する最小単位)まで分割して、それぞれの品詞や読みに関する情報まで付与してくれます。
このことを形態素解析と呼び、これをやってくれるマシンのことを形態素解析エンジンと呼びます。
代表的な形態素解析エンジンにMeCab、JUMAN、Sudachi、Janomeなどがあります。
私自身はMeCabとJanomeをよく使いますが、今回はMeCabを使ってやっていきたいと思います。MeCabは導入がOSによってかなりめんどくさいようです。特にwindowsがかなり大変らしいです。
私はmacとubuntuに導入しておりますが、windowsは試したことがございません。
導入方法は調べてやっていただきたいと思います。
Janomeは導入が大変手軽でwindowsにも試したことがありますが、性能でいうとMeCabに劣りますし、実用にはちょっと向かないかなと思います。手軽さは圧倒的ですが!この点は本当に素晴らしい。
一方のMeCabは実用にも十分耐えうる高性能な形態素解析エンジンです。
男は黙ってサッポロビールを形態素解析してみよう!
では、「男は黙ってサッポロビール」を形態素解析してみましょう。
import MeCab
tagger = MeCab.Tagger()
print(tagger.parse('男は黙ってサッポロビール'))
▼出力結果
男 名詞,一般,*,*,*,*,男,オトコ,オトコ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
黙っ 動詞,自立,*,*,五段・ラ行,連用タ接続,黙る,ダマッ,ダマッ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
サッポロビール 名詞,固有名詞,組織,*,*,*,サッポロビール,サッポロビール,サッポロビール
EOS
ご覧のような結果が出力されましたが、けっこうな量の情報が出てきました。
フォーマットは以下の通り!
MeCab出力フォーマット
表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
さて初回ということで、形態素解析の結果のありがたみをより一層実感するため、より分かりやすく見るため、Pandasを使って表示させてみましょう。
import pandas as pd
import re
tagger = MeCab.Tagger()
datas = tagger.parse('男は黙ってサッポロビール')
datas = datas.splitlines() # 改行にて分割
datas = datas[:-1] # EOSより前を取得
datas = [re.split(r'\t|,', data) for data in datas] # タブまたはカンマで分割
cols = [
'表層形',
'品詞',
'品詞細分類1',
'品詞細分類2',
'品詞細分類3',
'活用型',
'活用形',
'原形',
'読み',
'発音',
]
pd.DataFrame(datas, columns=cols)
▼出力結果
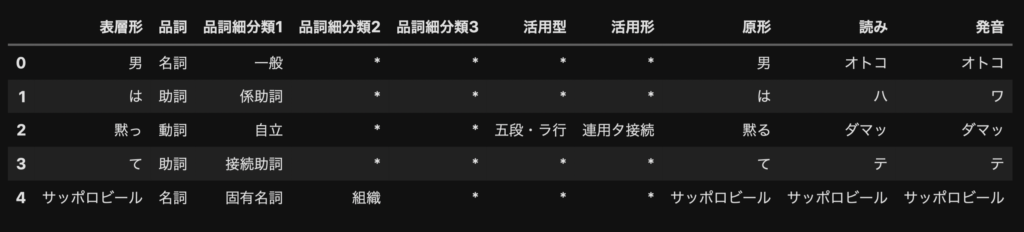

見やすくなりました。
この中の列で、表層形、品詞、原形は今後、色々なことに使えます。
例えば、「文章から名詞だけを抽出する」とかだけでも色々できそうな気がしませんか?
続く…


コメント