
こんにちは!monachan_papaです。
前回は男は黙ってサッポロビールを形態素解析してみよう!についてやりました。
今回はもう少し長めの自分が気になる文章や好きな文章を使って、形態素解析で色々遊んでみたいと思います。
今回の想定目標は以下のとおりです!
文章から名詞、動詞、形容詞の原形を取り出して、Pandasで可視化する。
テキストファイルの読み込み
形態素解析したい文章として、『雪国』川端康成の冒頭を選んでみました。
夜の底、という比喩がとてつもなく好きです!!
国境の長いトンネルを抜けると雪国であった。夜の底が白くなった。信号所に汽車が止まった。
向側の座席から娘が立って来て、島村の前のガラス窓を落した。
この冒頭を事前に yukiguni.txt という名前でテキストファイルに用意しておきます。
用意できたら、一気に読み込みんで表示してみます。
with open('yukiguni.txt', 'r') as f:
yukiguni = f.read()
print(yukiguni)
▼出力結果
国境の長いトンネルを抜けると雪国であった。夜の底が白くなった。信号所に汽車が止まった。
向側の座席から娘が立って来て、島村の前のガラス窓を落した。
変数yukiguniに冒頭文が入っているので、前回の復習を兼ねて、このあと形態素解析してみます。
とりあえず形態素解析するには?
前回の手法で、とりあえず形態素解析してみます。
import MeCab
t = MeCab.Tagger()
print(t.parse(yukiguni))
▼出力結果
記号,空白,*,*,*,*, , ,
国境 名詞,一般,*,*,*,*,国境,コッキョウ,コッキョー
の 助詞,格助詞,一般,*,*,*,の,ノ,ノ
長い 形容詞,自立,*,*,形容詞・アウオ段,基本形,長い,ナガイ,ナガイ
トンネル 名詞,一般,*,*,*,*,トンネル,トンネル,トンネル
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
抜ける 動詞,自立,*,*,一段,基本形,抜ける,ヌケル,ヌケル
と 助詞,接続助詞,*,*,*,*,と,ト,ト
雪国 名詞,一般,*,*,*,*,雪国,ユキグニ,ユキグニ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
あっ 助動詞,*,*,*,五段・ラ行アル,連用タ接続,ある,アッ,アッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
夜 名詞,副詞可能,*,*,*,*,夜,ヨル,ヨル
の 助詞,連体化,*,*,*,*,の,ノ,ノ
底 名詞,一般,*,*,*,*,底,ソコ,ソコ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
白く 形容詞,自立,*,*,形容詞・アウオ段,連用テ接続,白い,シロク,シロク
なっ 動詞,自立,*,*,五段・ラ行,連用タ接続,なる,ナッ,ナッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
信号 名詞,一般,*,*,*,*,信号,シンゴウ,シンゴー
所 名詞,接尾,一般,*,*,*,所,ショ,ショ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
汽車 名詞,一般,*,*,*,*,汽車,キシャ,キシャ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
止まっ 動詞,自立,*,*,五段・ラ行,連用タ接続,止まる,トマッ,トマッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
記号,空白,*,*,*,*, , ,
向 名詞,固有名詞,地域,一般,*,*,向,ムコウ,ムコー
側 名詞,接尾,一般,*,*,*,側,ガワ,ガワ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
座席 名詞,一般,*,*,*,*,座席,ザセキ,ザセキ
から 助詞,格助詞,一般,*,*,*,から,カラ,カラ
娘 名詞,一般,*,*,*,*,娘,ムスメ,ムスメ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
立っ 動詞,自立,*,*,五段・タ行,連用タ接続,立つ,タッ,タッ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
来 動詞,非自立,*,*,カ変・来ル,連用形,来る,キ,キ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
、 記号,読点,*,*,*,*,、,、,、
島村 名詞,固有名詞,人名,姓,*,*,島村,シマムラ,シマムラ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
前 名詞,副詞可能,*,*,*,*,前,マエ,マエ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
ガラス 名詞,一般,*,*,*,*,ガラス,ガラス,ガラス
窓 名詞,一般,*,*,*,*,窓,マド,マド
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
落し 動詞,自立,*,*,五段・サ行,連用形,落す,オトシ,オトシ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
EOS
説明のためにたった2行の冒頭文だけにしてみましたが、けっこうな量ですね。
さて、この例ではparseメソッドを使用していますが、今回の想定目標を達成するには、改行やタブの区切りなどの処理をする必要があり、何かと面倒です。
そこで、今回はもっと加工するのに扱いやすいparseToNodeメソッドを使います。
parseToNodeメソッドによる形態素解析
最終的な可視化までは以下の手順で行います。
- parseToNodeメソッドで形態素解析し、Nodeオブジェクトを得る
- Nodeオブジェクトのsurfaceプロパティにアクセス(表層形が得られる)
- Nodeオブジェクトのfeatureプロパティにアクセス(品詞や活用形が得られる)
- featureプロパティから品詞と原形を得る
- Nodeオブジェクトの最後まで繰り返す
- Pandasで可視化する
では、実際に一気に実装してみます。
import MeCab
import pandas as pd
t = MeCab.Tagger()
node = t.parseToNode(yukiguni)
result = []
while node:
# 表層形
surface = node.surface
# 品詞や活用情報など
feature = node.feature.split(',')
# 品詞、原形
pos, origin = feature[0], feature[6]
# 指定品詞のみ。原形があるなら原形、ない場合は表層形
if pos in ['名詞', '動詞', '形容詞']:
word = origin if origin != '*' else surface
result.append([word, pos, 1])
node = node.next
# 結果表示
df = pd.DataFrame(result, columns=['原形', '品詞', '出現回数'])
df.groupby(['品詞', '原形']).count()
▼出力結果
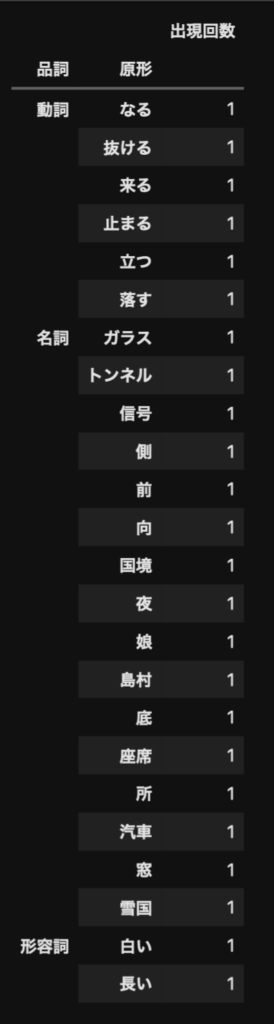
ソースのコメントと合わせて、解説します。
parseToNodeメソッドを使うと、表層形と品詞や活用情報などが初めから分離して取得できるのがとても便利です。
featureプロパティでインデックス番号を指定して、品詞と原形それぞれにアクセスします。
その後、if文で条件に合致するものをリストへ追加処理をしています。このとき、同時に出現回数として1も追加していきます。
結果的に出現回数はどれも1回でしたが、文章量が増えるとこの出現回数が重要になってきます。
その辺りについては、また別の機会で書きたいと思います。
見出し語化対応
さて、名詞、動詞、形容詞の原形を取得するのが、今回の想定目標でした。
なぜ原形を採用しているのかには理由があります。
活用による語形変化の補正をするためです。
これを見出し語化と呼びます。
以下の例で、「飲んだ」と「飲みました」に注目してください!
import MeCab
t = MeCab.Tagger()
print(t.parse('ビール飲んだ'))
print(t.parse('ビール飲みました'))
▼出力結果
ビール 名詞,一般,*,*,*,*,ビール,ビール,ビール
飲ん 動詞,自立,*,*,五段・マ行,連用タ接続,飲む,ノン,ノン
だ 助動詞,*,*,*,特殊・タ,基本形,だ,ダ,ダ
EOS
ビール 名詞,一般,*,*,*,*,ビール,ビール,ビール
飲み 動詞,自立,*,*,五段・マ行,連用形,飲む,ノミ,ノミ
まし 助動詞,*,*,*,特殊・マス,連用形,ます,マシ,マシ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
EOS
表層形が異なりますよね。後に続く単語に合わせて語形が変化しているわけですが、飲むという行為自体には変わりはありません。
他にも色々と理由はありますが、今回の話題とは逸れるので割愛します。
でも、一つだけ言っておきたいことがあります!
単純に可視化した際、表層形をそのまま使って、「飲ん」とか出るのは何かダサいよなあという私のこだわりです!可視化するということは、それなりに見栄えをよくすること大切だと思うんです。
見た目にこだわりたいですよね、こだわるときは。
続く…


コメント